
ChⅣ-数据库设计与实现
数据集设计方案
包括:
- 数据库应用架构设计
- 在不同应用需求场景中,数据库的应用架构方式是不同的。数据库应用架构可分为单用户结构、集中式结构、C/S 结构和分布式结构
- 数据库结构模型设计
- 数据库结构模型设计一般分为概念层、逻辑层、物理层设计,它们的设计模型分别为概念数据模型 CDM、逻辑数据模型 LDM 和物理数据模型 PDM
- 数据库应用访问方式设计
- 数据库应用对数据库访问可以有多种方式,如直接本地接口连接访问、基于标准接口连接访问、基于数据访问层框架连接访问
数据库结构模型
- 概念数据模型(Concept Data Model,CDM)是一种面向用户的系统数据模型,它用来描述现实世界的系统概念化数据结构。使数据库设计人员在系统设计的初始阶段,摆脱计算机系统及 DBMS 的具体技术问题,集中精力分析业务数据以及数据之间的联系等,描述系统的数据对象及其组成关系。
- 逻辑数据模型 (Logic Data Model,LDM)是在概念数据模型基础上,从系统设计角度描述系统的数据对象组成及其关联结构,并考虑这些数据对象符合数据库对象的逻辑表示。
- 物理数据模型(Physical Data Model,PDM)是在逻辑数据模型基础上,针对具体 DBMS 所设计的数据模型。它用于描述系统数据模型在具体 DBMS 中的数据对象组织、存储方式、索引方式、访问路径等实现信息。
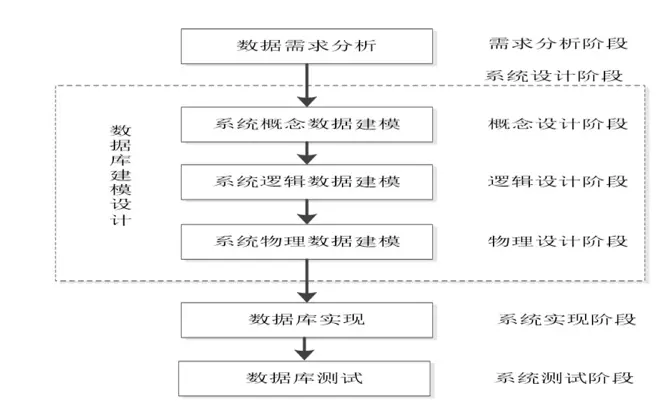
- 数据需求分析阶段:从现实业务中获取数据表单、报表、查询、业务规则、数据更新的说明;分析系统的数据特征、数据类型、数据取值约束;描述系统的数据关系、数据处理要求;建立系统的数据字典
- 数据库设计阶段:数据库内部结构设计(概念数据模型、逻辑数据模型、物理数据模型);数据库索引、视图、查询设计;数据库表约束设计;数据库触发器、存储过程设计;文件组织方式
- 数据库实现阶段:数据库创建;数据模型的 SQL 程序创建、数据库对象物理实现
- 数据库测试阶段:数据库数据上线;数据库系统测试
CDM 从用户角度所建模的系统数据对象及其关系,它帮助用户分析信息系统的数据结构关系 LDM 从系统分析员角度所建模的系统数据对象逻辑结构关系,它帮助开发人员分析信息系统的逻辑数据结构 PDM 从系统设计人员角度所建模的系统数据物理存储及结构关系,它针对设计者具体定义信息系统的数据库表结构
E-R 模型方法
E-R 模型基本元素
E-R 模型是“实体-联系模型”(Entity-Relationship Model)的简称。它是一种描述现实世界概念数据模型、逻辑数据模型的有效方法。
在 E-R 模型中,基本元素包括实体、属性、标识符和联系:
- 实体Entity 是指问题域中存在的人、事、物、地点等客观事物在逻辑层面的数据抽象。它用于描述事物的数据对象,如客户、交易、产品、订单等
- 属性Attribute 是指描述实体特征的数据项。每个实体都具有 1 个或多个属性
- 标识符Identifier 是指标识不同实体实例的属性。标识符可以是 1 个或多个属性
标识符与主键的区别是标识符是一个逻辑概念,主键是物理概念 - 联系Relationship 是指实体之间的联系,如“学生”与“成绩”的联系、“孩子”与“父亲”、“母亲”的联系等。
联系中关联的实体数目称为联系度数
实体-联系类型
二元实体联系类型
- 一对一联系 1:1
- 一对多联系 1:N
- 多对多联系 M:N
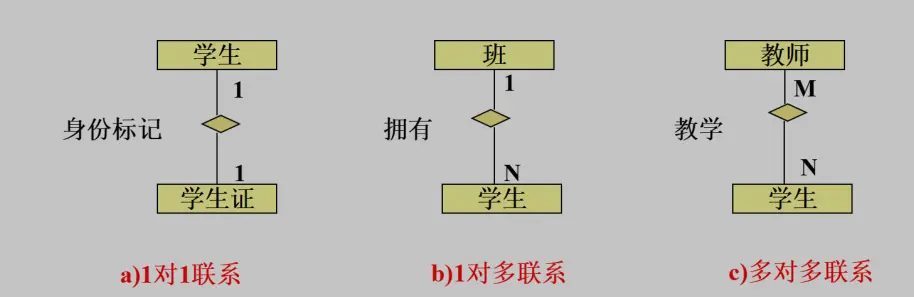
上述实体之间的联系反映了一个给定实体有多少实例与另一实体实例存在的数量对应关系。术语基数Cardinality 表示实体联系的实例数量。在实体之间除了需要反映了数量对应关系,有时还需要反映实体参与关系的必要性,即可选optional 或强制mandatory
继承联系
在 E-R 模型中,实体之间除了基本联系外,还存在继承联系。继承联系用于表示实体之间的相似性关系。在实体继承联系中,一端是具有公共属性的实体,称为父实体;另一端是与父实体具有相似属性,同时也具有特殊性的一个或多个实体,称为子实体。
在继承联系中,还可以分为:
- 互斥性继承联系Mutual Exclusive Inheritance Relationship:在这种类型的继承中,子类只能从一个父类继承,不能同时从多个父类继承
- 非互斥性继承联系Non-Mutual Exclusive Inheritance Relationship:这种类型的继承中,子类可以从多个父类继承,即一个子类可以属于多个父类
- 完整继承联系 Total Inheritance Relationship:在这种继承中,父实体的每一个实例都必须是一个或多个子实体的实例。换句话说,父实体中的每个 instance 都必须在子实体中有对应。例如,如果我们有一个“人”实体,它有两个子实体:“学生”和“教师”,那么在完整继承关系中,每个“人”都必须是“学生”或“教师”。
- 不完整继承联系 Partial Inheritance Relationship:在这种类型的继承中,子类的 instance 可以不属于父类的任何子类;在上述的例子中,非完整继承允许存在一些“人”,他们既不是“学生”也不是“教师”。

强弱实体联系
在 E-R 模型中,按照实体之间的语义关系,可以将实体分为弱实体 Weak Entity 和强实体 Strong Entity; 弱实体是指那些对于另外实体有依赖关系的实体,即一个实体的存在必须以另一实体的存在为前提。而被依赖的实体称为强实体; 例如在学校与学生之间的联系中,学生是弱实体,学校是强实体。
- 强实体Strong Entity
- 弱实体Weak Entity
- 标识符依赖弱实体 Identifier Dependent Weak Entity
如果弱实体的标识符中,包含了强实体的标识符,那么这种弱实体称为标识符依赖弱实体 - 非标识符依赖弱实体 Non-Identifier Dependent Weak Entity
如果弱实体的标识符中,不包含强实体的标识符,那么这种弱实体称为非标识符依赖弱实体
- 标识符依赖弱实体 Identifier Dependent Weak Entity
数据库建模设计
概念数据模型设计是通过对现实世界中数据实体进行抽取、分类、聚集和概括等处理,建立反映系统业务数据组成结构的过程。
步骤
- 业务数据分析,抽取数据实体
- 定义实体属性及其标识
- 建立实体联系,构建局部 E-R 模型图
- 分类、聚集和概括各个部分 E-R 模型图
- 完善全局 E-R 模型图,建立系统业务数据组成结构
数据模型 DM 元素对应关系表
| CDM | LDM | PDM |
|---|---|---|
| Entity | Entity | Table |
| Attribute | Attribute | Column |
| Identifier | Primary Identifier/Foreign Identifer | Primary Key/Foreign Key |
| Relationship | Relationship | Reference(参照完整性约束) |
1:1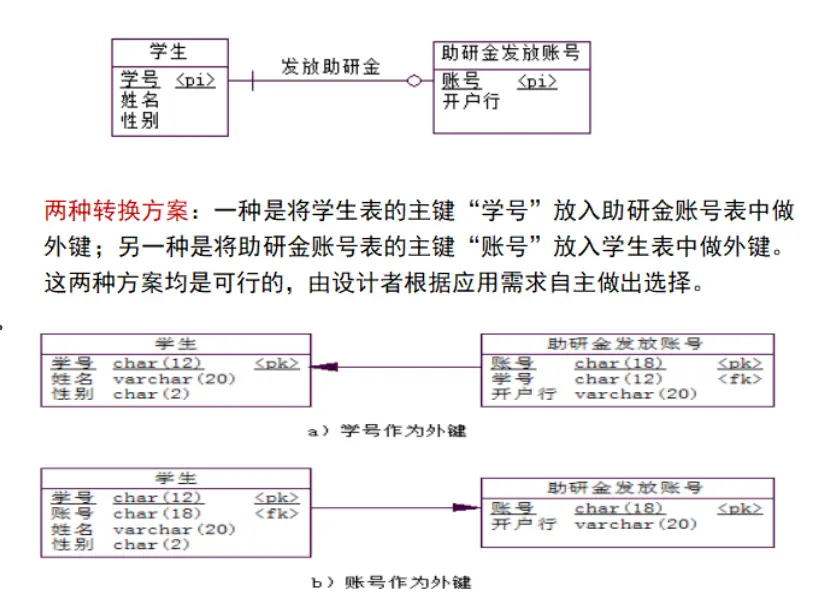
1:N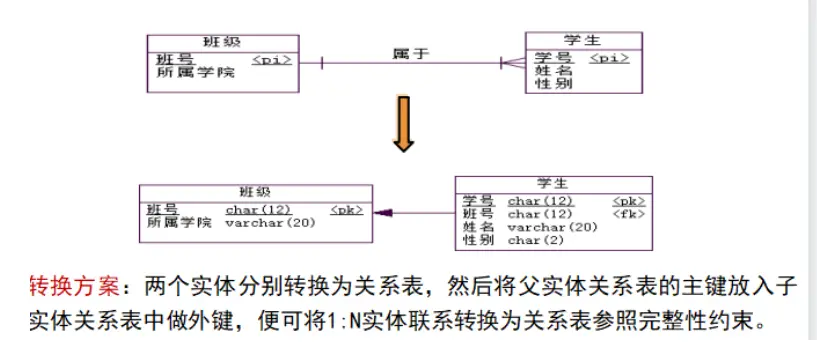
M:N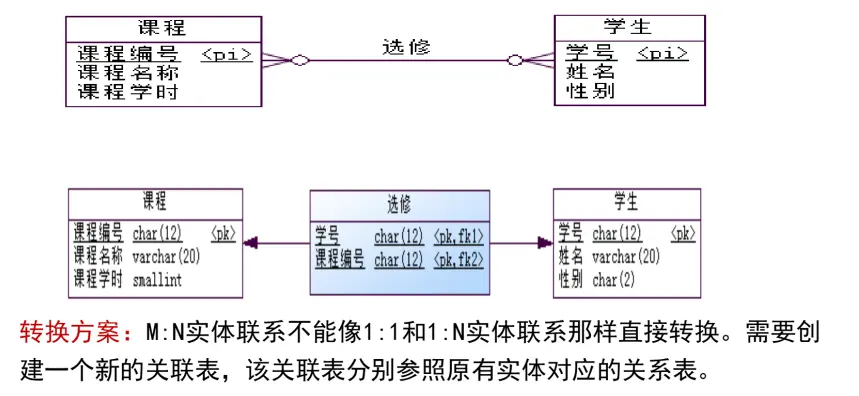
规范化设计
为什么需要规范化数据库设计?
- 减少数据库中的冗余数据,尽量使同一数据在数据库中仅保存一份,有效降低维护数据一致性的工作量。
- 设计合理的表间依赖关系和约束关系,便于实现数据完整性和一致性。
- 设计合理的数据库结构,便于系统对数据高效访问处理。
函数依赖
定义:设有一关系模式R(U),U 为关系 R 的属性集合,X和Y为属性U的子集。设 t,s 是关系 R 中的任意两个元组,如果 t[X] = s[X],则t[Y] = s[Y]。那么称 Y 函数依赖于 X,表示为X→Y。
函数依赖的左部称为决定因子,右部称为依赖函数。决定因子和依赖函数都是属性的集合。
假设我们有一个关系模式
R,代表一个学生注册系统,其中U是关系R的属性集合,包括{学生ID, 姓名, 课程ID, 课程名, 教师}
任意给定两个元组t和s,例如
元组t:{学生ID: 001, 姓名: "小明", 课程ID: C101, 课程名: "数学", 教师: "李老师"}
元组s:{学生ID: 001, 姓名: "小明", 课程ID: C102, 课程名: "英语", 教师: "王老师"}
都有t[学生ID] = s[学生ID] 则 t[姓名] = s[姓名]
可以得出学生 ID 决定姓名,即学生ID→姓名
函数依赖的类型:
- 完全函数依赖 Total Functional Dependency
若X→Y,对于X的任何一个真子集X',X'→Y都不成立,则称X→Y是完全函数依赖 - 部分函数依赖 Partial Functional Dependency
若X→Y,X存在一个真子集X',使得X'→Y,则称X→Y是部分函数依赖 - 属性传递依赖 Transitive Dependenc
若满足X→Y,Y→Z,则有X→Z,则称为属性传递依赖 - 多值函数依赖 Multivalued Dependency
设 U 是关系模式 R 的属性集,X 和 Y 是 U 的子集,Z=U-X-Y,xyz表示属性集 XYZ 的值。对于 R 的关系 r,在 r 中存在元组(x, y1, z1)和(x, y2, z2)时,也存在元组(x, y1, z2)和(x, y2, z1),那么在模式 R 上存在多值函数依赖。(数据结构,李老师,《数据结构与算法-初级》)
(数据结构,王老师,《数据结构与算法-高级》)
(数据结构,李老师,《数据结构与算法-高级》)
(数据结构,王老师,《数据结构与算法-初级》)
关系规范化范式
关系规范化是把一个有访问异常的关系分解成结构良好的关系的过程,使得这些关系有最小的冗余或没有冗余。
规范化范式(Normal Form,NF)是指关系表符合特定规范化程度的模式。
- 第 1 范式(1NF)
如果关系表中的属性不可再细分,该关系满足第 1 范式。反之,该表就不是关系表。如果联系方式是一个关系表的属性,那么联系方式还可细分为电话号码、邮箱等属性;消除联系方式这类属性,将联系方式细分为电话号码、邮箱等属性,就满足了第 1 范式。
- 第 2 范式(2NF)
如果关系满足第 1 范式,并消除了关系中的属性部分函数依赖,该关系满足第 2 范式。有一个关系(A,B,N, 0,P)其复合主键为(A,B)那么N,O,P这三个非键属性都不存在只依赖 A 或只依赖 B 情况,则该关系满足第 2 范式,反之,不满足第 2 范式。我们有一个关系模式 R,它的属性集 U 包括 {学生 ID, 课程 ID, 学生姓名, 课程名, 教师},复合主键为(学生 ID,课程 ID),然而学生姓名只依赖于学生 ID,课程名和教师只依赖于课程 ID,那么学生姓名和课程名、教师之间存在部分函数依赖,不满足第 2 范式。
- 第 3 范式(3NF)
如果关系满足第 2 范式,并切断了关系中的属性传递函数依赖,该关系满足第 3 范式。{学号,姓名,系名,住址(宿舍地址),电话,电子邮件},其中学号决定系名,系名决定宿舍地址,故学号决定宿舍地址,存在传递依赖,不满足第 3 范式;可以对学生关系表再次分解为学生和系信息关系表

- Boyce-Codd 范式(BCNF)
在关系中,所有函数依赖的决定因子都是候选键,该关系满足 BCNF 范式 - 第 4 范式(4NF)
如果关系满足 BCNF 范式,并消除了多值函数依赖,该关系满足第 4 范式。
逆规范化处理
所谓逆规范化,就是适当降低规范化范式约束,不再要求一个关系表必须达到很高的规范化程度,而是允许适当的数据冗余性,以获取数据访问性能。
逆规范化处理的基本方法:
(1)增加冗余列或派生列
(2)多个关系表合并为一个关系表