网络编程相关基础知识 Endianness 字节 (Byte) 传输和存储信息的最小单位。各种数据类型,都是由字节构成。
字节序 (Endianness)是指在计算机内存中多字节数据类型的存储方式,主要涉及到高位字节和低位字节的排列顺序。字节序主要分为两大类:大端字节序(Big-Endian)和小端字节序(Little-Endian),另外还有较少使用的中端字节序(Middle-Endian)
Big-Endian 在大端字节序中,数据的高位字节存储在内存的低地址处,而低位字节存储在高地址处。这种存储方式与我们日常书写数字的习惯相匹配,即从左至右,高位在前,低位在后。例如,对于 32 位整数 0x12345678,在大端字节序下的内存布局为:
1 2 3 4 地址递增方向 --> +--------+--------+--------+--------+ | 0x12 | 0x34 | 0x56 | 0x78 | +--------+--------+--------+--------+
Little-Endian 小端字节序则相反,低位字节存储在内存的低地址处,高位字节存储在高地址处。这是大多数现代个人电脑和嵌入式系统的处理器所采用的方式,如 x86 架构。对于同样的 32 位整数 0x12345678,在小端字节序下的内存布局为:
1 2 3 4 地址递增方向 --> +--------+--------+--------+--------+ | 0x78 | 0x56 | 0x34 | 0x12 | +--------+--------+--------+--------+
Network-Endian 由于不同机器可能采用不同的字节序,为了正确的传输数据,需要一个统一的标准。因此数据在网络中传输时,需要转换为网络字节序 Network-Endian 。
网络字节顺序是 TCP/IP 中规定好的一种数据表示格式,它与具体的 CPU 类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。
网络字节顺序采用 Big-Endian 排序方式,总是从低位地址开始传输。
发送数据包时,程序将主机字节序转换为网络字节序;接受收数据包时,则将网络字节序转换为主机字节序。
字节序变换 如何检查主机字节序?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <stdio.h> int main (int argc, char **argv) { union { short s; char c[sizeof (short )]; } un; un.s = 0x0102 ; if (sizeof (short ) == 2 ) { if (un.c[0 ] == 1 && un.c[1 ] == 2 ) printf ("big-endian\n" ); else if (un.c[0 ] == 2 && un.c[1 ] == 1 ) printf ("little-endian\n" ); else { printf ("unknown\n" ); } } else { printf ("sizeof(short) = %d\n" , sizeof (short )); } exit (0 ); }
字节序的变换函数htons(3) - Linux man page
1 2 3 4 5 6 7 #include <arpa/inet.h> uint16_t htons (uint16_t hostshort) uint32_t htonl (uint32_t hostlong) uint16_t ntohs (uint16_t netshort) uint32_t ntohl (uint16_t netlong)
C 函数库特有高浓度缩写,初见实在令人发指
htons : host to network shorthtonl : host to network longntohs : network to host shortntohl : network to host long
标准库中通常只提供 16 位(htons)和 32 位(htonl)字节序转换函数的实现,下面是long long的字节序转换函数
1 2 3 4 5 6 7 8 9 10 11 #include <arpa/inet.h> #include <inttypes.h> uint64_t htonll (uint64_t hostlonglong) { return (((uint64_t ) htonl(hostlonglong)) << 32 ) + htonl(hostlonglong >> 32 ); } uint64_t ntohll (uint64_t networklonglong) { return (((uint64_t ) ntohl(networklonglong)) << 32 ) + ntohl(networklonglong >> 32 ); }
此处以一个实例演示htonll的工作流程,假设本地为小段模式,12 34 56 78存储形式为78,56,34,12htonl(hostlonglong)即htonl(78563412),参数为 long long 越界,返回结果为 1234,转成 long long 后左移 32 位htonl(hostlonglong >> 32)即htonl(7856),返回 567812 34 56 78,成功转为大端模式,即网络序
Data Alignment 数据结构对齐 是操作系统为了快速访问内存⽽采取的⼀种策略,简单来说,就是为了防止内存的⼆次访问。操作系统在访问内存时,每次读取⼀定的长度(这个长度就是操作系统的默认对齐系数,或者是默认对齐系数的整数倍)。如果没有内存对齐时,为了读取⼀个变量,会产⽣内存的⼆次访问。
对齐系数
每个特定平台的编译器都有自己的默认“对齐系数” 。
通过预编译命令#pragma pack(n),n=1,2,4,8,16 来改变这一系数,其中的 n 就是指定的“对齐系数”。
结构体对齐规则 :最宽基本类型成员 的大小所整除;
在 64 位的 Linux 机器上,以下结构到底 size 多少?
1 2 3 4 5 6 7 8 9 10 11 struct X2 {char a; int b; char c; };struct X3 {int a; char b; };struct X4 {char a; short b; };struct X5 {char a; short b; char c; };struct X6 {char a; long b; };struct X7 {char a; long b; char c; };struct X8 {char a; long long b; };struct X9 {char a; long long b; char c; };struct X10 {char a; int b; short c; };struct X11 {char a; short b; char c; int d; };
struct X2: 包含 1 字节的 char,4 字节的 int,和 1 字节的 char。整体需要 4 字节对齐(因为 int),所以 char a 之后会有 3 字节填充。总大小 = 1 (a) + 3 (padding for a) + 4 (b) + 1 (c) = 9 字节,但为了满足 4 字节对齐,末尾还需补足到 4 字节的倍数,最终大小为 12 字节。
struct X3: 包含 4 字节的 int 和 1 字节的 char。整体需要 4 字节对齐,char b 之后会有 3 字节填充。总大小 = 4 (a) + 1 (b) + 3 (padding for b) = 8 字节。
…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <stdio.h> struct X2 {char a; int b; char c; };struct X3 {int a; char b; };struct X4 {char a; short b; };struct X5 {char a; short b; char c; };struct X6 {char a; long b; };struct X7 {char a; long b; char c; };struct X8 {char a; long long b; };struct X9 {char a; long long b; char c; };struct X10 {char a; int b; short c; };struct X11 {char a; short b; char c; int d; };int main () { printf ("Size of struct X2: %zu bytes\n" , sizeof (struct X2)); printf ("Size of struct X3: %zu bytes\n" , sizeof (struct X3)); printf ("Size of struct X4: %zu bytes\n" , sizeof (struct X4)); printf ("Size of struct X5: %zu bytes\n" , sizeof (struct X5)); printf ("Size of struct X6: %zu bytes\n" , sizeof (struct X6)); printf ("Size of struct X7: %zu bytes\n" , sizeof (struct X7)); printf ("Size of struct X8: %zu bytes\n" , sizeof (struct X8)); printf ("Size of struct X9: %zu bytes\n" , sizeof (struct X9)); printf ("Size of struct X10: %zu bytes\n" , sizeof (struct X10)); printf ("Size of struct X11: %zu bytes\n" , sizeof (struct X11)); return 0 ; } ~> ./a.out Size of struct X2 :12 bytes Size of struct X3 :8 bytes Size of struct X4 :4 bytes Size of struct X5 :6 bytes Size of struct X6 :16 bytes Size of struct X7 :24 bytes Size of struct X8 :16 bytes Size of struct X9 :24 bytes Size of struct X10 :12 bytes Size of struct X11 :12 bytes
接口协议
TCP/IP 协议存在于 OS 中,网络服务通过 OS 提供
TCP/IP 要尽量避免让接口使用某一个厂商的 OS 中特有的特征(而其他厂商没有)
TCP/IP 和应用程序之间的接口应该不精确指明:
不规定接口的细节
只建议需要的功能集
允许系统设计者选择有关 API 的具体实现细节
不精确指明的协议接口有以下 Pros&Cons
优点:提供了灵活性和容错能力
便于各种 OS 实现 TCP/IP
接口可以是过程的,也可以是消息的
缺点:不同的 OS 中的接口细节不同
接口协议举例:
Berkeley UNIX 中的套接字接口
Microsoft Windows 中的 Windows Socket
接口协议的功能
分配用于通信的本地资源
指定本地和远程通信端点
(客户端)启动连接
(客户端)发送数据报
(服务器端)等待连接到来
发送或者接收数据
判断数据何时达
产生紧急数据
处理到来的紧急数据
从容终止连接
处理来自远程端点的连接终止
异常终止通信
处理错误条件或者连接异常终止
连接结束后释放本地资源
POSIX
POSIX 表示可移植操作系统接口
Portable Operating System Interface of UNIX(缩写为 POSIX )
POSIX 标准定义了操作系统应该为应用程序提供的接口标准,是 IEEE 为要在各种 UNIX 操作系统上运行的软件而定义的一系列 API 标准的总称,其正式称呼为 IEEE 1003,而国际标准名称为 ISO/IEC 9945。
POSIX 标准意在期望获得源代码级别的软件可移植性。
为一个 POSIX 兼容的操作系统编写的程序,应该可以在任何其它的 POSIX 操作系统(即使是来自另一个厂商)上编译执行。
POSIX 并不局限于 UNIX
许多其它的操作系统,例如 DEC OpenVMS 也支持 POSIX 标准。
System Call
操作系统内核提供一系列具备预定功能的内核函数,通过称为系统调用(System Call)的接口呈现给用户。
为安全考量,诸如 I/O 操作等特权指令被限制在内核态模式执行
系统调用使得应用程序从操作系统获得服务。
LINUX 中提供的基本 I/O 功能
六个基本的系统 I/O 函数:
函数
含义
Open
为输入或输出操作准备一个设备或者文件
Close
终止使用以前已打开的设备或者文件
Read
从输入设备或者文件中得到数据
Write
数据从应用程序存储器传到设备或文件中
Lseek
转到文件或者设备中的某个指定位置
loctl
控制设备或者用于访问该设备的软件
[[Ch7-1LinuxUnix#文件 I/O]]
扩展文件描述符,可用于网络通信
扩展 read,write,可用于操作网络标识符
额外功能的处理,通过增加新系统调用实现:
使用 TCP 还是 UDP
指明本地和远端的端口,远程 IP 地址
启动传输还是等待传入连接
可以接受多少传入连接
传输 UDP 数据
Socket 基本概念 协议操作接口,而非协议本身
Berkeley UNIX Sockets API BSD,Berkeley Software Distribution
主动 Socket 和被动 Socket
创建方式相同,使用方式不同
被动:等待传入连接的套接字,如服务器套接字
主动:发起连接的套接字,如客户端套接字
指明端到端地址:创建时不指定,使用时指明(TCP/IP 需要指明协议端口号和 IP 地址)
TCP/IP 协议族:PF_INET
TCP/IP 地址族:AF_INET
Socket 类型
套接字支持多种通信协议:
Unix: Unix 系统内部协议
INET: IP 版本 4
INET6:IP 版本 6
套接字类型,即应用程序希望的通信服务类型
SOCKET_DGRAM: 双向不可靠数据报,对应 UDP;DGRAM 即 datagram
SOCKET_STREAM:双向可靠数据流,对应 TCP
SOCKET_RAW:低于传输层的低级协议或物理网络提供的套接字类型,可以访问内部网络接口。
地址结构 Socket 通用地址结构 sockaddr
Socket 是传输层/网络层编程接口,由于传输层/网络层的各种实现不同,可能会有不同的编址方案。通用地址为了适应这种需求而定义。
通用地址有很大局限性,实际并不具有通用性,例如针对 AF_INET6/AF_LOCAL 类型的 Socket 地址,sockaddr 结构实际上只能标识出这个地址的类型。
Socket IPv4 IPv6 地址结构与通用结构
早期 sockaddr 只包含 2 个字节的 sa_family 和后面的 14 个字节的 data,后来为了 OSI 兼容性,第一个字节变为长度 len,值为 16,相应的,sa_family 变为 1 个字节;
如今 sockaddr 仅在 bind 等函数里,传递参数时强制类型转换使用,其它没啥用途(因为早期的 C 没有 void 指针,即通用指针,所以搞得那么麻烦);
Ipv4 用的是 sockaddr_in,里面的 len 和 sockaddr 的 len 一样含义;sa_family 改名为 sin_family,值为 AF_INET 了
地址转换函数
人们习惯使用 202.112.14.151 表示地址(点分十进制),但是这个本质是一个字符串而不是数值,因此在 socket 编程时,需要进行转换。此外还要考虑字节序的问题,为此可以使用如下一些函数:
inet_aton 这堆函数,仅在处理网络参数时使用,比如 IP 地址,端口等。而在用 I/O 函数接收发送数据时,不用考虑字节序问题,OS 自动处理。
函数中的 Aton 指阿托恩,是古埃及信奉的太阳神 address to network address
1 2 3 4 5 6 7 8 9 10 11 #include <arpa/inet.h> int inet_aton (const char *cp, struct in_addr *inp) in_addr_t inet_addr (const char *cp) char *inet_ntoa (struct in_addr in)
上述三个地址转换函数都只能处理 IPv4 协议,而不能处理 IPv6 地址。在同时要处理 IPv4 和 v6 的程序中,建议使用以下两个函数。
1 2 3 4 5 6 7 8 9 10 11 12 int inet_pton (int family, const char *src, void *dst) inet_pton (AF_INET, "192.168.1.1" , &srv_addr.sin_addr) const char *inet_ntop (int family, const void *src, char *dst, size_t cnt) printf ("[srv] server[%s:%d] is initializing!\n" , inet_ntoa(srv_addr.sin_addr), ntohs(srv_addr.sin_port)) ;
上面两个函数名称可以分解为两部分来理解其含义inet: 这个前缀来源于“Internet”,表明这个函数是与互联网相关的,特别是与 IP 地址处理有关。在套接字编程的上下文中,“inet”通常指代与互联网协议相关的函数或操作。pton: 是“Presentation to Network”的缩写,意味着该函数将人类可读的表示形式(即“Presentation”层的数据,如 IP 地址的点分十进制字符串形式)转换为适合在网络上传输的二进制格式(即“Network”层的数据)。简而言之,“pton”类型的函数负责从应用层的表示形式转换到网络层的传输格式。
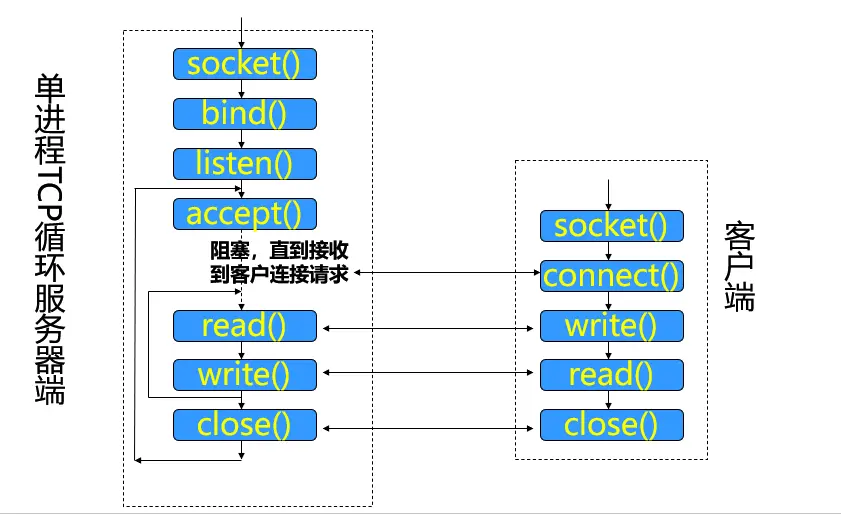
Socket 套接字与循环服务器 简单 TCP 循环服务器 Socket 编程基本步骤
创建套接字
绑定套接字
设置套接字为监听模式,进入被动接受连接状态
接受请求,建立连接
读写数据
终止连接
创建套接字
与远程服务器建立连接
读写数据
终止连接
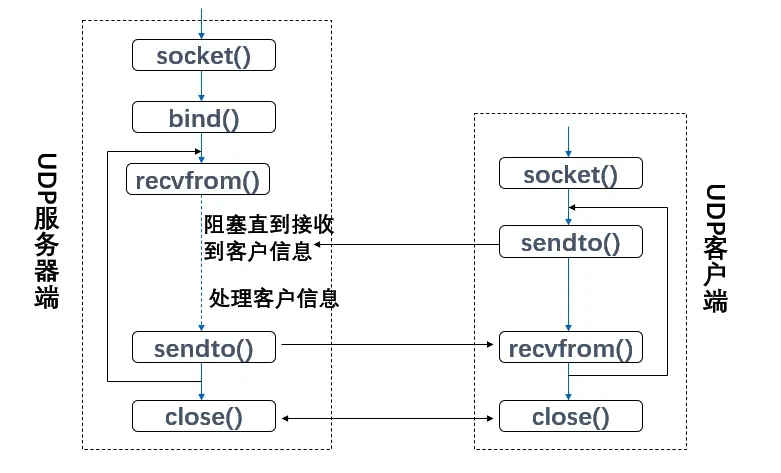
简单 UDP 循环服务器 Socket 编程基本步骤
建立 UDP 套接字;
绑定套接字到特定地址;
等待并接收客户端信息;
处理客户端请求;
发送信息回客户端;
关闭套接字;
建立 UDP 套接字;
发送信息给服务器;
接收来自服务器的信息;
关闭套接字
Socket 核心函数 socket() 功能:创建一个套接字,返回套接字描述符
参数:
family:指明使用的协议栈,如 TCP/IP 使用的是 PF_INET 或 AF_INETtype: 指明需要的服务类型, 如:SOCK_DGRAM,数据报服务,UDP 协议SOCK_STREAM ,流服务,TCP 协议protocol:IP 报头中的协议字段,一般取 0
1 2 3 #include <sys/socket.h> int socket (int family, int type, int protocol) ;
bind() 功能:将 socket 与本地 address 关联,指定这个套接字应该监听哪个 IP 地址上的哪个端口传入的连接请求
参数:
sockfd,Socket File Descriptor,套接字描述符,指明创建连接的套接字myaddr,本地地址,IP 地址和端口号addrlen ,地址长度
你可能会疑惑,fd 是什么鬼(╬▔ 皿 ▔)╯
1 2 3 #include <sys/socket.h> int bind (int sockfd, const struct sockaddr *myaddr, socklen_t addrlen) ;
listen() 功能:用于服务器,指明某个套接字连接是被动的,并准备接收传入连接。
参数:
Sockfd:套接字描述符,指明创建连接的套接字backlog:该套接字使用的队列长度,指定在请求队列中允许的最大请求数
TCP 为监听套接字维护的两个队列,已完成连接队列(ESTABLISHED 状态)和未完成连接队列(SYN_RCVD 状态),已建立连接队列长度不能超过 backlog
1 2 3 #include <sys/socket.h> int listen (int sockfd, int backlog) ;returns: 0 OK, -1 on error
accept() 功能:
参数
sockfd: 这是通过 socket()函数创建并用 bind()函数绑定了特定地址,然后用 listen()函数设置为监听模式的套接字描述符。cliaddr: 这是一个指向 sockaddr 结构体的指针,用于接收客户端的地址信息。当函数返回时,这个结构体会被填充为客户机的地址信息。addrlen: 地址长度
connect() 功能:
参数:
sockfd,套接字描述符,指明创建连接的套接字servaddr,指明远端 IP 地址和端口号addrlen,地址长度
1 2 3 #include <sys/socket.h> int connect (int sockfd, const struct sockaddr *servaddr, socklen_t addrlen) ;returns: 0 if OK, -1 on error
客户端调用该函数发起向服务器的连接
客户端可以不必再调用 bind 来绑定地址
应用程序会阻塞,直到连接建立,或者出现异常:
超时,6s/24s/75s,ETIMEOUT
RST,服务器没有开启服务,ECONNREFUSED
ICMP 错误,路由出错,EHOSTUNREACH/ ENETUNREACH
特别注意:connect 失效后,不能再次调用 connect 试图重建连接,而必须:调用 close(),socket(),connect()重连
send() & sendto() send()
sockfd,套接字描述符data,指向要发送数据的指针data_len,数据长度flags,一般为 0
1 2 #include <sys/socket.h> int send (int sockfd, const void * data, int data_len, unsigned int flags)
sendto()
功能:
参数:
sockfd,套接字描述符data,指向要发送数据的指针data_len,数据长度flags,一般为 0remaddr,远端地址:IP 地址和端口号remaddr_len ,地址长度
1 2 #include <sys/socket.h> int sendto (int sockfd, const void * data, int data_len, unsigned int flags, struct sockaddr *remaddr, int remaddr_len)
recv() & recvfrom() recv()
参数:
Sockfd:套接字描述符Buf:指向内存块的指针Buf_len:内存块大小,以字节为单位flags:一般为 0
1 2 #include <sys/socket.h> int recv (int sockfd, void *buf, int buf_len,unsigned int flags) ;
recvfrom()
功能:
参数:
Sockfd:套接字描述符buf:指向内存块的指针buf_len:内存块大小,以字节为单位flags:一般为 0from:远端的地址,IP 地址和端口号fromlen:远端地址长度
1 2 #include <sys/socket.h> int recvfrom (int sockfd, void *buf, int buf_len, unsigned int flags, struct sockaddr *from, int fromlen) ;
close() 功能:
参数:sockfd:套接字描述符
1 2 3 #include <unistd.h> Int close (int sockfd) ; returns: 0 if OK, -1 on error
Example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 #include <arpa/inet.h> #include <errno.h> #include <inttypes.h> #include <netinet/in.h> #include <signal.h> #include <stdint.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> void handle_sigint (int sig) ;int parse_requests (int connfd) ;void print_result (char *data, int64_t *res) ;uint64_t htonll (uint64_t host_64) ;uint64_t ntohll (uint64_t net_64) ;uint64_t htonll (uint64_t val) { return (((uint64_t )htonl(val)) << 32 ) + htonl(val >> 32 ); } uint64_t ntohll (uint64_t val) { return (((uint64_t )ntohl(val)) << 32 ) + ntohl(val >> 32 ); } struct sockaddr_in srv_addr ;struct sockaddr_in cli_addr ;socklen_t cli_addr_len = sizeof (cli_addr);int sigint_flag = 0 ;int main (int argc, char **argv) { signal(SIGPIPE, SIG_IGN); struct sigaction sa ; sa.sa_flags = 0 ; sa.sa_handler = handle_sigint; sigemptyset(&sa.sa_mask); sigaction(SIGINT, &sa, NULL ); int listenfd = socket(AF_INET, SOCK_STREAM, 0 ); memset (&srv_addr, 0 , sizeof (srv_addr)); srv_addr.sin_family = AF_INET; srv_addr.sin_port = htons(atoi(argv[2 ])); inet_pton(AF_INET, argv[1 ], &srv_addr.sin_addr); bind(listenfd, (struct sockaddr *)&srv_addr, sizeof (srv_addr)); listen(listenfd, 10 ); printf ("[srv] server[%s:%d] is initializing!\n" , inet_ntoa(srv_addr.sin_addr), ntohs(srv_addr.sin_port)); while (!sigint_flag) { int connfd; if ((connfd = accept(listenfd, (struct sockaddr *)&cli_addr, &cli_addr_len)) < 0 ) { if (errno == EINTR) { continue ; } else { perror("[debug] accept error" ); exit (1 ); } } printf ("[srv] client[%s:%d] is accepted!\n" , inet_ntoa(cli_addr.sin_addr), ntohs(cli_addr.sin_port)); parse_requests(connfd); close(connfd); } printf ("[srv] listenfd is closed!\n" ); close(listenfd); printf ("[srv] server is going to exit!\n" ); return 0 ; } int parse_requests (int connfd) { while (1 ) { char buffer[24 ] = {0 }; int len = read(connfd, buffer, 24 ); if (len == 0 ) { printf ("[srv] client[%s:%d] is closed!\n" , inet_ntoa(cli_addr.sin_addr), ntohs(cli_addr.sin_port)); return 0 ; } int64_t result; print_result(buffer, &result); uint64_t res_network = htonll(result); write(connfd, &res_network, sizeof (res_network)); } } void handle_sigint (int sig) { printf ("[srv] SIGINT is coming!\n" ); sigint_flag = 1 ; } void print_result (char *data, int64_t *res) { int32_t op_int = *(int32_t *)data; int32_t op = ntohl(op_int); uint64_t a_net = *(uint64_t *)(data + sizeof (op_int)); int64_t a = ntohll(a_net); uint64_t b_net = *(uint64_t *)(data + sizeof (op_int) + sizeof (a)); int64_t b = ntohll(b_net); char op_symbol; switch (op) { case 0x00000001 : op_symbol = '+' ; *res = a + b; break ; case 0x00000002 : op_symbol = '-' ; *res = a - b; break ; case 0x00000004 : op_symbol = '*' ; *res = a * b; break ; case 0x00000008 : op_symbol = '/' ; *res = a / b; break ; case 0x00000010 : op_symbol = '%' ; *res = a % b; break ; } printf ("[rqt_res] %" PRId64 " %c %" PRId64 " = %" PRId64 "\n" , a, op_symbol, b, *res);}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 #include <arpa/inet.h> #include <errno.h> #include <inttypes.h> #include <netinet/in.h> #include <stdint.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> struct sockaddr_in srv_addr ;void handle_sigint (int sig) ;void send_requests (int connfd) ;uint64_t htonll (uint64_t host_64) ;uint64_t ntohll (uint64_t net_64) ;int connfd;uint64_t htonll (uint64_t val) { return (((uint64_t )htonl(val)) << 32 ) + htonl(val >> 32 ); } uint64_t ntohll (uint64_t val) { return (((uint64_t )ntohl(val)) << 32 ) + ntohl(val >> 32 ); } int main (int argc, char **argv) { sigemptyset(&sa.sa_mask); sigaction(SIGINT, &sa, NULL ); memset (&srv_addr, 0 , sizeof (srv_addr)); srv_addr.sin_family = AF_INET; srv_addr.sin_port = htons(atoi(argv[2 ])); inet_pton(AF_INET, argv[1 ], &srv_addr.sin_addr); connfd = socket(AF_INET, SOCK_STREAM, 0 ); connect(connfd, (struct sockaddr *)&srv_addr, sizeof (srv_addr)); printf ("[cli] server[%s:%d] is connected!\n" , inet_ntoa(srv_addr.sin_addr), ntohs(srv_addr.sin_port)); send_requests(connfd); close(connfd); printf ("[cli] connfd is closed!\n" ); printf ("[cli] client is going to exit!\n" ); } void send_requests (int connfd) { while (1 ) { char data[50 ] = {0 }; fgets(data, 50 , stdin ); if (strncmp (data, "EXIT" , 4 ) == 0 ) { printf ("[cli] command EXIT received\n" ); close(connfd); break ; } char op[5 ], op_symbol; int32_t op_idx; int64_t a, b; sscanf (data, "%s %" PRId64 " %" PRId64, op, &a, &b); if (strcmp (op, "ADD" ) == 0 ) { op_idx = 0x00000001 ; op_symbol = '+' ; } else if (strcmp (op, "SUB" ) == 0 ) { op_idx = 0x00000002 ; op_symbol = '-' ; } else if (strcmp (op, "MUL" ) == 0 ) { op_idx = 0x00000004 ; op_symbol = '*' ; } else if (strcmp (op, "DIV" ) == 0 ) { op_idx = 0x00000008 ; op_symbol = '/' ; } else if (strcmp (op, "MOD" ) == 0 ) { op_idx = 0x00000010 ; op_symbol = '%' ; } else { ; } char *req_pdu = (char *)malloc (150 ); uint32_t net_op_idx = htonl(op_idx); uint64_t net_a = htonll(a); uint64_t net_b = htonll(b); memcpy (req_pdu, &net_op_idx, sizeof (net_op_idx)); memcpy (req_pdu + sizeof (net_op_idx), &net_a, sizeof (net_a)); memcpy (req_pdu + sizeof (net_op_idx) + sizeof (net_a), &net_b, sizeof (net_b)); write(connfd, req_pdu, sizeof (net_op_idx) + sizeof (net_a) + sizeof (net_b)); free (req_pdu); uint64_t result_net; read(connfd, &result_net, sizeof (result_net)); int64_t result; result = ntohll(result_net); printf ("[rep_rcv] %" PRId64 " %c %" PRId64 " = %" PRId64 "\n" , a, op_symbol, b, result); } }
多进程、多线程并发服务器设计 迭代服务器的特点
多用户的情况下,连接建立后,若没有 accept,连接存放在 listen 函数队列
accept 从已完成队列的对头摘取新套接字
对客户端的服务是一个串行(serial)的过程
采用多进程的方式引入并行
可用 fork()实现多进程并发,或用 Pthreads 库实现多线程并发
I/O 模型以及基于 I/O 复用的并发服务器设计 五种 I/O 模式
阻塞 I/O (Linux 下的 I/O 操作默认是阻塞 I/O,即 open 和 socket 创建的 I/O 都是阻塞 I/O)
非阻塞 I/O (可以通过 fcntl 或者 open 时使用 O_NONBLOCK 参数,将 fd 设置为非阻塞的 I/O)
I/O 多路复用 (I/O 多路复用,通常需要非阻塞 I/O 配合使用)—select,poll,epoll
信号驱动 I/O (SIGIO)
异步 I/O
同步 IO 和异步 IO
IO 的两个阶段都没有被阻塞,才能被称为异步 IO
阻塞 I/O 模式 阻塞 IO 是最通用的 IO 类型,使用这种模型进行数据接收的时候,在数据没有到之前程序会一直等待。例如对于函数 recvfrom(),内核会一直阻塞该请求直到有数据到来才返回。
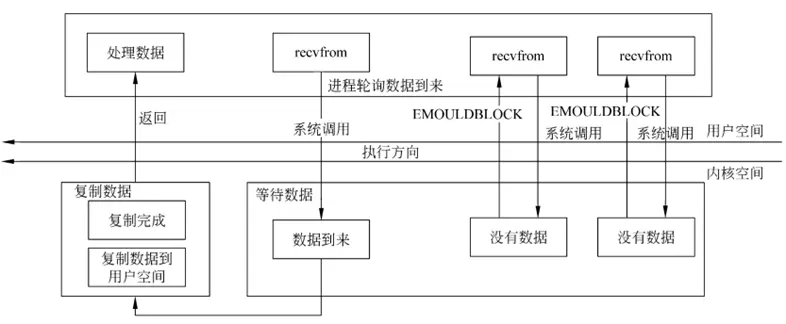
非阻塞 I/O 模式 当把套接字设置成非阻塞的 IO,则对每次请求,内核都不会阻塞,会立即返回;当没有数据的时候,会返回一个错误。例如对 recvfrom()函数,前几次都没有数据返回,直到最后内核才向用户层的空间复制数据。
非阻塞模式的使用并不普遍,因为非阻塞模式会浪费大量的 CPU 资源。
当我们将一个套接字设置为非阻塞模式,我们相当于告诉了系统内核: “当我请求的 I/O 操作不能够马上完成,你想让我的进程进行休眠等待的时候,不要这么做,请马上返回一个错误给我。”
我们开始对 recvfrom 的第二次调用,因为系统还没有接收到网络数据,所以内核马上返回一个 EWOULDBLOCK 的错误。
第三次我们调用 recvfrom 函数,一个数据报已经到达了,内核将它拷贝到我们的应用程序的缓冲区中,然后 recvfrom 正常返回,我们就可以对接收到的数据进行处理了。
当一个应用程序使用了非阻塞模式的套接字,它需要使用一个循环,以监听测试是否一个文件描述符有数据可读(称做 polling,轮询)。应用程序不停的 polling 内核来检查是否 I/O 操作已经就绪。这将是一个极浪费 CPU 资源的操作。这种模式使用中不是很普遍。
I/O 多路复用 I/O 多路复用的原理是为了避免 CPU 空转,使用一个代理(select/poll/epoll..)同时观察许多流的 I/O 事件,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中醒来,于是我们的程序就会轮询一遍所有的流。例如 select()函数按照一定的超时时间轮询,直到需要等待的套接字有数据到来,利用 recvfrom()函数,将数据复制到应用层。
为了避免 CPU 空转,可以引进了一个代理(一开始有一位叫做 select 的代理,后来又有一位叫做 poll 的代理,不过两者的本质是一样的)。这个代理比较厉害,可以同时观察许多流的 I/O 事件,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中醒来,于是我们的程序就会轮询一遍所有的流。
select 能等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
但是使用 select,有 O(n)的无差别轮询复杂度,同时处理的流越多,轮询时间就越长。
epoll 可以理解为 event poll,不同于忙轮询和无差别轮询,epoll 之会把哪个流发生了怎样的 I/O 事件通知我们。此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
信号驱动 IO 模型 信号驱动的 IO 在进程开始的时候注册一个信号处理的回调函数,进程继续执行,当信号发生时,即有了 IO 的时间,这里即有数据到来,利用注册的回调函数将到来的数据用 recvfrom()接收到。
所谓信号驱动,就是利用信号机制,安装信号 SIGIO 的处理函数(进行 IO 相关操作),通过监控文件描述符,当其就绪时,通知目标进程进行 IO 操作(signal handler)
异步 IO 模型 异步 IO 与前面的信号驱动 IO 相似,其区别在于信号驱动 IO 当数据到来的时候,使用信号通知注册的信号处理函数,而异步 IO 则在数据复制完成的时候才发送信号通知注册的信号处理函数。
Linux 上异步 IO 有一组 POSIX 规定的接口,以 aio 开头的几个 SYSCALL。如下:
1 2 3 int aio_read (struct aiocb *aiocbp) ;int aio_write (struct aiocb *aiocbp) ;ssize_t aio_return (struct aiocb *aiocbp) ;
客户端&服务器程序设计&核心问题解析 服务器特权和复杂性
服务器经常需要访问受操作系统保护的资源:需要系统特权
服务器不能把特权传递给使用服务的客户
服务器需要处理的安全问题:
鉴别:验证客户身份
授权:判断某个客户是否可以使用服务器提供的服务
数据安全:确保数据不被无意泄漏或者损坏
保密:防止未经授权访问信息
保护:确保网络程序不能滥用系统资源
特权和并发导致了服务器软件的复杂性
核心设计问题
通信模式与协议
C/S vs. P2P
传输层 UDP vs.TCP
应用层协议交互流程
应用层协议 PDU 设计
客户端程序设计
如何指定服务器
PDU 的解析处理与构建
是否需要多进程或多线程设计
如何结束通信
服务器程序设计
如何指定监听地址
PDU 的解析处理与构建
循环 vs. 并发?若并发:多进程 vs. 多线程 vs. I/O 复用
注册登录用户如何管理
数据如何转发
Ref 扩展了解:关于 PF_INET 和 AF_INET 的区别 (AF 是 BSD 规范,PF 是 posix 规范)Socket 通信中 AF_INET 和 AF_UNIX 域的区别 浅谈 uint8_t 等以_t 结尾的数据类型 一文理解可重入函数