
网络层控制平面 Network Layer:Control Plane
Introduction
路由算法确定了通过网络的端到端路径,转发表确定了在路由器上的本地转发,转发表是链接数据平面与控制平面的主要元素,本篇将介绍其是如何计算、维护的
- 每个路由器控制 Per-router control:每台路由器有一个路由选择组件,用于与其他路由器中的路由选择组件通信,以计算其转发表的值。
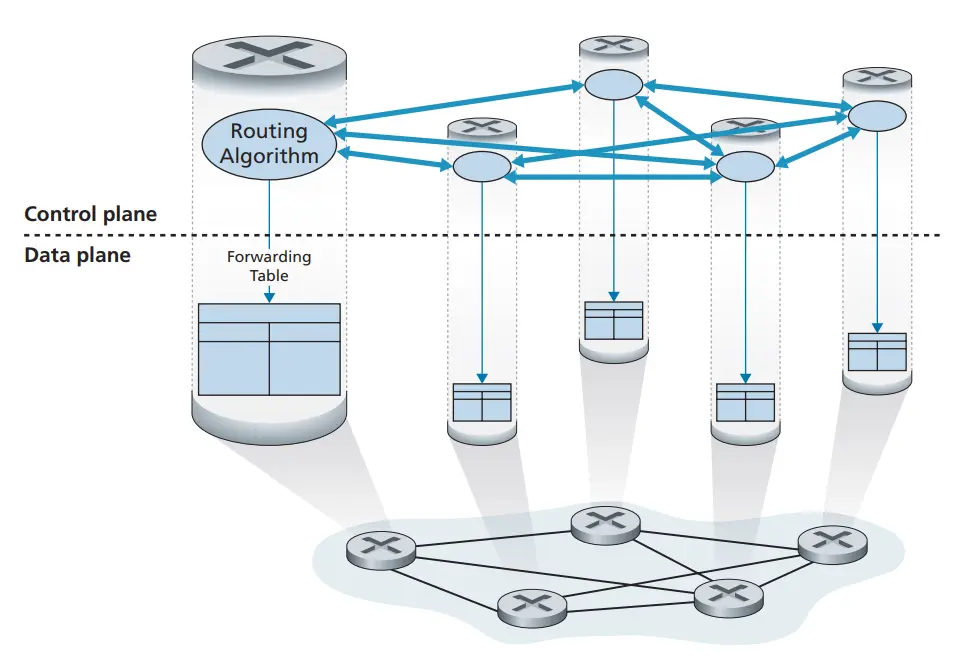
- 逻辑集中式控制 Logically centralized control:逻辑集中式控制器计算并分发转发表以供每台路由器使用,如下图所示:

Routing Algorithms
路由的基本概念
- 默认路由器:与主机直接相连的路由器,又叫第一跳路由器。每当主机发送一个分组时,都先传送给它的默认路由器。
- 源路由器:源主机的默认路由器。
- 目的路由器:目的主机的默认路由器。
- 从源主机到目的主机的选路归结为从源路由器到目的路由器的选路。
- 路由算法:是确定一个分组从源路由器到目的路由器所经路径的算法
- 路由算法的关键:在给定的一组路由器以及连接路由器的链路中,找到一条从源路由器到目的路由器的“好”路径。
网络的抽象图模型
图$G = (N,E)$表示 N 个节点和 E 条边的集合,每条边是来自 N 的一对节点。
Node 节点:表示路由器(做出分组转发判决的点)。如 $u,v,w,x,y,z$
Edge 边:连接节点的线段,表示路由器之间的物理链路。如$(u,v)、 (u,x) 、(u,w)、…$
Cost 可以表示对应链路的物理长度、或链路速度、或与链路相关的费用。
定义:$c(x,y)$ 表示从节点 x 到节点 y 的链路费用,规定若节点 x 与节点 y 不直接相连则$c(x,y)=\infty$
Routing Algorithms Classification
- 集中式路由选择算法 Centralized Routing Algorithm:用完整、全局性的网络知识计算出从源到目的地之间的最低开销路径。具有全局状态信息的算法常被称作链路状态(Link State,LS)算法,因为该算法必须知道网络中每条链路的开销。
- 分布式路由算法 Decentralized Routing Algorithm:路由器以迭代、分布式计算的方式计算出最低开销路径。没有节点拥有关于网络链路开销的完整信息。一个分散式路由选择算法为距离向量(Distance-Vector,DV)算法,每个节点维护到网络中所有其他节点的开销估计的向量。
- 静态路由算法:路由确定后基本不再变化。只有人工干预调整时,可能有一些变化。
- 动态路由算法:当网络的流量负载或拓扑发生变化时,路径可能发生改变。可以周期性地或直接地响应拓扑或链路费用的变化。易受选路循环、路由振荡之类问题的影响。
Link State Routing Algorithms
链路状态选路算法
在实践中,这经常由链路状态广播(link state broadcast)算法完成。下面给出的链路状态路由选择算法是 Dijkstra’s algorithm
Dijkstra’s Alogorithm
- 所有节点知道网络拓扑,以及每条链路的费用信息
- 通过链路状态广播来实现
- 所有节点拥有相同的信息
- 计算任意一个节点(源节点)到所有其他节点的最低费用路径
- 给出该节点的转发表
- 迭代:通过 k 次迭代后可以知道到达 k 个目的节点的最低费用路径
- 基本思想:以源节点为起点,每次找出一个到源节点的费用最低的节点,直到把所有的目的节点都找到为止。
定义以下符号
c(x,y): 表示从节点 x 到节点 y 的链路费用,规定若节点 x 与节点 y 不直接相连则c(x,y)=∞D(v):到算法的本次迭代,从源节点到目的节点 v 的最低开销;p(v):从源到 v 沿着当前最小开销路径的前一个节点(v 的邻居);N':节点子集;如果从源到 v 的最低开销路径已经确定,v 在N'中u源节点
Link-State (LS) Algorithm for Source Node u
1 | Initialization: |
以上图为例,计算从u到所有可能目的节点的最低费用路径。算法迭代如下


构建从源节点到所有目的节点的路径
- 对于每个节点,都得到从源节点沿着它的最低费用路径的前驱节点;
- 每个前驱节点,又可得到它的前驱节点;以此继续,可以得到到所有目的节点的完整路径。
如节点 z 的前驱节点依次为:p(z)=y,z->y;p(y)=x,z->y->x;p(x)=u,z->y->x->u - 得出从源节点 u 到节点 z 的最低费用路径为:uxyz,费用为 4。
- 根据目的节点找出顺序和其费用以及前驱节点,可以画出源节点 u 到所有目的节点的最低费用路径树。
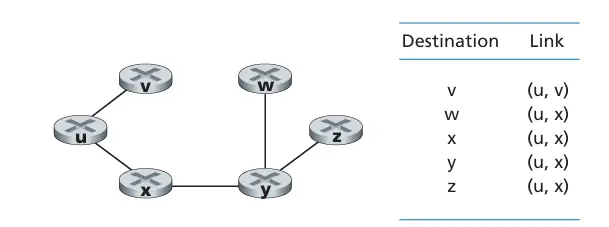
- 根据得到的所有目的节点的完整路径,或最低费用路径树,可以生成源节点的转发表。转发表存放从源节点到每个目的节点的最低费用路径上的下一跳节点。即指出对于发往某个目的节点的分组,从该节点发出后的下一个节点。
默认路由
*:表示所有具有相同“下一跳”的表项。即将“下一跳”相同的项合并为一项,目的节点用*表示。优先级最低,转发分组时,当找不到对应表项时,才使用默认路由。
Dijkstra’s Algorithm 复杂度
设 n 个节点(除源节点),最坏情况下要经多少次计算才能找到从源节点到所有目的节点的最低费用路径?
第一次迭代:搜索所有的 n 个节点以确定最低费用节点
第二次迭代:检查 n-1 个节点;
第三次:检查 n-2 个节点;
依次类推。
所有迭代中需要搜寻的节点总数为 $\frac{n(n+1)}{2}$
算法复杂性为 $O(n^2)$
且路线上的流量变化和拥塞会使 LS 算法产生路由震荡 Routing Oscillations
The Distance-Vector(DV)Routing Algorithm
距离向量路由算法有以下特征
- 迭代 Iterative:计算过程一直持续到邻居之间无更多信息交换为止。
- 分布式 Distributed:每个节点都从其直接相连邻居接收信息,进行计算,再将计算结果分发给邻居。
- 异步 Asynchronous:不要求所有节点相互之间步伐一致地操作。
- 自我终结 Self-termination:算法能自行停止。
Bellman-Ford 方程
$$d_x(y)=min_v{c(x,v)+d_v(y)}$$
- $d_x(y)$:节点 x 到节点 y 的最低开销路径的 cost。
- $v$: 节点 x 的邻居节点。
- $c(x,v)+ d_v(y)$:x 与某个邻居 v 之间的直接链路费用 c(x,v)加上邻居 v 到 y 的最小费用。即 x 经 v 到节点 y 的最小的路径费用。
- $min_v$ :从所有经直接相连邻居节点到节点 y 的费用中选取的最小路径费用。
Distance-Vector (DV) Algorithm

对每个节点 x:
- 初始化
- 等待 (收到本地链路代价变化或邻居来距离矢量更新)
- 重新计算距离矢量,更新距离向量
- 如果到任何目的节点的距离矢量发生变化, 通知邻居
- goto2
仍以该图为例,计算源节点u到目的节点z的最低费用路径。
- 邻居 v:$d_v(z) = 5、c(u,v) = 2$
- 邻居 w:$d_w(z) = 3、c(u,w) = 5$
- 邻居 x:$d_x(z) = 3、c(u,x) = 1$
即源节点 u 经相邻节点 x 到目的节点 z 的路径费用最低,为 4
节点的距离向量表
- 行:该节点的距离向量 Dx 和其邻居的距离向量 Dv
- 列:所有目的节点。
节点 x 的距离向量 $D_x$ ,即节点 x 到每个目的节点 y 的估计费用; $Dx = [D_x(y) | y \in N ]$
节点 x 每个邻居的距离向量 $D_v$ ,即 x 的邻居 v 到每个目的节点 y 的估计费用,$Dv = [D_v(y):y \in N]$
如何更新距离向量?
- 每个节点不断向邻居发送其距离向量的 copy;
- 当节点 x 收到一个邻居 v 的新距离向量,先保存,并用 B-F 公式更新自己的距离向量:
$D_x(y)=min_v{c(x,v)+D_v(y)}$
从所有经邻居 v 到节点 y 的费用中选取最小路径费用 - 若距离向量发生改变,将新的距离向量通知给邻居。
- 当距离向量不再变化,算法终止,此时$D_x(y)$收敛到$d_x(y)$,即得到节点 x 到节点 y 的最低费用路径。
- 多次重复从邻居接收更新距离向量、重新计算选路表项、并向邻居发送更新通知的过程,直到没有更新报文
- 算法进入静止状态,直到某个链路费用发生改变为止。


Distance-Vector Algorithm: Link-Cost Changes and Link Failure
当一个节点检测到从它到邻居的链路费用发生变化时,就更新其距离向量,如果最低费用路径的费用发生变化,通知其邻居。
某链路费用减少时情况
如图所示,当 y 到 x 的链路费用从 4 变为 1 的情况。t0:y 检测到 x 的链路费用从 4 变为 1,更新其距离向量,并通知其邻居 z;t1:z 收到来自 y 的更新报文,并更新自己的距离表,此时到节点 x 的最低费用减为 2,并通知其邻居 y;t2:y 收到来自 z 的更新报文,并更新自己的距离表,此时到节点 x 的最低费用不变仍为 1。不发送更新报文,算法静止。
当 x 与 y 之间费用减少,DV 算法只需两次迭代到达静止状态。节点之间链路费用减少的“好消息”在网络中能迅速传播,即 good news travels fast
某链路费用增加时情况
假设 x 与 y 之间的链路费用从 4 增加到 60
链路费用变化前
$D_y(x)=4 ,D_y(z)=1, D_z(y)=1,D_z(x)=5$t0:y 检测到链路费用从 4 变为 60。更新到 x 的最低路径费用
$D_y(x)=min{c(y,x)+ D_x(x), c(y,z)+ D_z(x)}=min{60+0,1+5}=6$
此时 $D_y(x)=6 ,D_y(z)=1, D_z(y)=1,D_z(x)=5$
经节点 z 到 x 费用最低,此新费用错误,发给节点 z。t1:z 收到新费用,更新其到 x 的最低路径费用
$D_z(x )=min{ c(z,x)+ D_x(x), c(z,y)+ D_y(x)}=min{50+0,1+6}=7$
此时 $D_y(x)=6 ,D_y(z)=1, D_z(y)=1,D_z(x)=7$
经节点 y 到 x 费用最低,发给节点 y。t2:y 收到新费用,更新到 x 的最低路径费用
$D_y(x )=min{c(y,x)+ D_x(x), c(y,z)+ D_z(x)}=min{60+0,1+7}=8$
经节点 z 到 x 费用最低,发给节点 z。
……
节点 y 或 z 的最低费用不断更新。
产生选路回环(routing loop):为到达 x, y 通过 z 选路,z 又通过 y 选路。即目的地为 x 的分组到达 y 或 z 后,将在这两个节点之间不停地来回反复,直到转发表发生改变为止。上述循环将持续 44 次迭代 (y 与 z 之间的报文交换),直到 z 最终算出它经由 y 的路径费用大于 50 为止。并确定:z 到 x 的最低费用路径:zxy 到 x 的最低费用路径:yzx
说明:链路费用增加的“坏消息”传播很慢,即 bad news travels slow
当链路费用增加很大,会出现无穷计数(count-to-infinity)问题。如链路费用 c(y,x)变为 10000,c(z,x)变为 9999 时。
Distance-Vector Algorithm: Adding Poisoned Reverse
针对上面的问题,引出毒性逆转(poisoned reverse)思想:如果 z 通过 y 路由选择目的地 x,则 z 将通告 y,它到 x 的距离是无穷大,也就是 z 将通告$D_z(x)=\infty$。毒性逆转可以完全解决计数到无穷的问题吗?不能,如果三个以上节点的环路,则不能被毒性逆转技术检测
A Comparison of LS and DV Routing Algorithms
消息复杂度
LS 算法:知道网络每条链路的费用,需发送 $O(nE)$个报文;当一条链路的费用变化时,必须通知所有节点
DV 算法:迭代时,仅在两个直接相连邻居之间交换报文;当链路费用改变时,只有该链路相连的节点的最低费用路径发生改变时,才传播已改变的链路费用
收敛速度
LS 算法:需要 $O(nE)$个报文和 $O(n^2)$的搜寻,可能会振荡
DV 算法:收敛较慢。可能会遇到选路回环,或计数到无穷的问题。
健壮性
当一台路由器发生故障、操作错误或受到破坏时,会发生什么情况?
LS 算法:路由器向其连接的一条链路广播不正确费用,路由计算基本独立(仅计算自己的转发表),有一定健壮性。
DV 算法:一个节点可向任意或所有目的节点发布其不正确的最低费用路径,一个节点的计算值会传递给它的邻居,并间接地传递给邻居的邻居。一个不正确的计算值会扩散到整个网络。
Intra-AS Routing in the Internet: OSPF
迄今为止,我们的路由研究都是理想化的: 所有路由器一样的 网络是 “平面的” 实际中并不是这样的。互联网在规模上具有 20 亿个节点,路由表中不可能存储所有的节点而路由表的信息交换也将淹没数据链路
随着路由器规模增大和管理自治的要求,可以通过将路由器组织进自治系统(Autonomous System,AS)来解决。在一个自治系统内运行的路由算法叫做自治系统内部路由选择协议(intra-autonomous system routing protocol),不同自治系统内的路由器可以运行不同的区域内路由协议
网关路由器(gateway router)
- 和其他自治系统内的路由器直接相连的路由器。运行域间路由协议,与其他网关路由器交互
- 同自治系统内的所有其他路由器一样也运行域内路由协议
域(自治系统)内路由选择
- 使用域内路由协议,也被称作内部网关协议 (IGP)
- 标准的域内路由协议:
- RIP: 路由信息协议
- OSPF: 开放式最短路径优先
- IGRP: 内部网关路由协议 (Cisco 所有)
RIP ( Routing Information Protocol)
- 属于距离向量算法,包含在 1982 年发布的 BSD-UNIX 版本中。
- 距离衡量: 跳数 (max = 15 hops)
- RIP 通告
- 每隔 30 秒,通过响应报文在邻居间交换距离向量 (也被称为 RIP 通告, advertisement)
- 每个通告包含了多达 25 个 AS 内的目的子网的列表
- RIP 链路失败及恢复
若 180 秒后没有收到通告,则认为邻居死机或链路中断:- 通过故障邻居的路由失败
- 新的公告发送给其他邻居
- 邻居然后再发送新的公告 (如果转发表发生变化)
- 链路故障信息快速传播到整个网络
- 毒性逆转用于防止乒乓循环 (无限距离 = 16 跳)
OSPF (Open Shortest Path First)
OSPF 是一种链路状态协议,它使用洪泛链路状态信息和 Dijkstra 最低开销路径算法。使用 OSPF,一台路由器构建了一幅关于整个自治系统的完整拓扑图。于是,每台路由器在本地运行 Dijkstra 的最短路径算法,以确定一个自身为根节点到所有子网的最短路径树。
使用 OSPF 时,路由器向自治系统内所有其他路由器广播路由选择信息,而不仅仅是向其相邻路由器广播。每当一条链路的状态发生变化时,路由器就会广播链路状态信息。
- 属于链路状态算法
- 分发 LS 分组
- 每个节点具有拓扑图
- 路由计算使用 Dijkstra 算法
- 每个 router 都广播 OSPF 通告,OSPF 通告里为每个邻居路由器设一个表项(记录每个邻居的链路特征和费用)
- 通告会散布到 整个 自治系统 (通过洪泛法)
- OSPF 信息直接通过 IP 传输 (不是 TCP 或 UDP)
OSPF 相比 RIP 的优点
- 安全: 所有 OSPF 消息需要认证 (防止恶意入侵)
- 允许多个相同开销的路径 (在 RIP 中只有一条路径)
- 对于每个链路, 有多个消费尺度用于不同的服务类型 TOS (例如在尽力转发时卫星链路代价设置为 “低” ,而对实时应用设置为高)
- 对单播与多播路由选择的综合支持(Integrated support for unicast and multicast routing);
- 在大的区域中使用层次 OSPF
层次 OSPF
- 两级层次: 本地区域, 主干区域(这些区域都是在一个自治系统内)
- 只在区域内发送链路状态通告
- 每个节点有详细的区域拓扑; 仅知道到达其他区域内网络的方向(即最短路径)
- 区域边界路由器(同时属于本地区域和主干区域):“汇总”了到本区域内部网络的路径, 并通告给其他区域边界路由器.
- 主干路由器:限于在主干区域内运行 OSPF 路由协议(本身不是区域边界路由器)
- 边界路由器: 连接到其他自治系统

Routing Among the ISPs:BGP
当分组跨越多个 AS 进行路由时,我们需要一个自治系统间路由协议(inter-autonomous system routing protocol)。在因特网中,所有的 AS 运行相同的 AS 间路由选择协议,称为边界网关协议(Broder Gateway Protocol,BGP)。
The Role of BGP
BGP 是事实上的标准,它为每个 AS 提供了一种手段
- 从相邻 AS 获取子网的可达性信息 Obtain prefix reachability information from neighboring ASs,向该 AS 内部的所有路由器传播这些可达性信息 Advertising BGP Route Information。
- 基于该可达信息和 AS 策略,决定到达子网的“最好”路由 Determine the “best” routes to the prefixes.
In BGP, packets are not routed to a specific destination address, but instead to CIDRized prefixes, with each prefix representing a subnet or a collection of subnets.
BGP 是一种 AS(自治区域)外部路由协议,主要负责本自治区域和外部的自治区域间的路由可达信息的交换。因此,它所关心的拓扑结构是 AS(自治区域)的拓扑结构。转发表根据 AS 内和 AS 间选路算法而配置;AS 域内和 AS 域间的选路项用于目的端在域外的选路,AS 域内的选路项用于目的端在域内的选路。
假设 AS1 中的路由器接收到了目的端是 AS1 外的分组。路由器将把这个分组转发到网关路由器,但是是哪个网关路由器呢?
AS1 需要知道:
- 通过 AS2 和 AS3 可以到达哪些目的端
- 将这些可达信息传播给 AS1 内的所有路由器
这就是域间选路的任务
Advertising BGP Route Information
对于每个 AS,路由器可分为网关路由器 gateway router及内部路由器 internal router。在 BGP 中,每对路由器通过使用179端口的半永久 TCP 连接(semi-permanent TCP connections)交换路由选择信息,TCP 连接携带着 BGP message,因此其也称作BGP Connection。其中跨越两个 AS 的 BGP 连接称为eBGP connection,而在相同 AS 中的两台路由器之间的 BGP 会话称为iBGP connection。

以上图为例,具体传播过程如下:当需要将前缀 x 的可达性信息传播至 AS1 和 AS2 的所有路由器时,首先,AS3 的网关路由器 3a 通过 eBGP 发送消息AS3 x给 AS2 的网关路由器 2c。接着,路由器 2c 利用 iBGP 将此消息AS3 x转发给 AS2 内的所有其他路由器,包括路由器 2a。然后,路由器 2a 通过 eBGP 发出更新的消息AS2 AS3 x至 AS1 的网关路由器 1c。最后,路由器 1c 使用 iBGP 将这条包含路径信息的消息AS2 AS3 x广播给 AS1 内的所有路由器。完成这一过程后,AS1 和 AS2 中的每一台路由器都知晓了前缀 x 的存在及其可达的 AS 路径。
可达性信息通过 iBGP 和 eBGP 的协作,在自治系统内外进行传播,确保网络中的每个关键节点都能够了解到目标前缀的存在及其可达路径。
Determining the Best Routes
当通告前缀时,通告包含了 BGP 属性(BGP attribute),前缀+属性称为路由 route
两个重要的属性:1
- AS-PATH: 包含了前缀的通告已经通告过的那些 AS,如
AS 67 AS 17,BGP 也会根据 AS-PATH 属性来检测并避免循环通告 - NEXT-HOP: 指出到达下一个 AS 的具体 AS 间边界路由器(可能存在多条从当前 AS 到达下一个 AS 的链路)
当网关路由器接收到路由通告时,使用输入策略来决定接收/舍弃该通告。
Hot potato routing
热土豆(烫手山芋)路由选择的基本思想是:在多个 NEXT-HOP 路由器中,选择到 NEXT-HOP 开销最低的路径。
热土豆的思想:尽可能块地将分组送出其 AS(最低开销),而不担心其 AS 外部到目的地的余下部分的开销(贪心策略)
在路由器转发表中增加 AS 外部目的地的步骤:
Route-Selection Algorithm
路由器可能知道到相同前缀的多条路由,路由器必须从中选择。该种情况下会顺序地匹配下列消除规则
- 路由被指派一个本地偏好(local preference)值作为其属性值之一,具有最高本地偏好值的将被选择;
- 如果本地偏好值相同,则选择具有最短 AS-PATH 属性值的路由;
- 如果 AS-PATH 属性值相同,则选择具有最短 NEXT-HOP 属性值的路由;(Hot potato routing)
- 根据 BGP identifiers, 匹配其它标准
IP-Anycast
除了作为 Internet 的 AS 间路由协议外,BGP 还经常用于实现 IP 任播服务,该服务通常用于 DNS。
常见的应用场景可抽象为:在许多不同的分散地理位置的不同服务器上复制相同的内容,并让每个用户从最近的服务器访问内容。
具体的例子包括: CDN 可以在不同国家/地区的服务器上复制视频和其他对象。DNS 系统可以在世界各地的 DNS 服务器上复制 DNS 记录。
Routing Policy
X 是一个多宿主接入 ISP(multi-homed access ISP),它经由两个不同提供商连接到两个网络
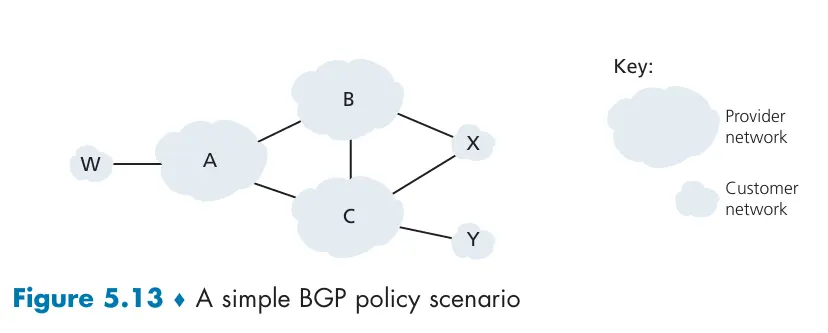
- B 向X通告路由BAW
- A 向B通告路径 AW
- B 会向C通告路由BAW吗?
- W和C都不是B的customer,B希望C通过A路由到W(CAW),自己只负责路由自己的客户
ISP遵循的法则:任何穿越某ISP主干网的流量必须是其源或者目的位于该ISP的某个客户网络中
为什么 AS 内选路和 AS 间选路采用不同的协议?
- 策略 Policy:
- AS 间: 管理员想控制本 AS 内产生的通信流怎样选路,以及什么通信流穿过自己的网络
- AS 内:单个管理者, 因此不需要策略
- 规模 Scale:
- 层次路由节省了转发表的大小空间,减少了路由更新的流量
- 性能 Performance:
- AS 内: 集中在性能上
- AS 间: 策略可能比性能更加重要
The SDN Control Plane
软件定义网络(SDN,SoftwareDefinedNetwork)源自美国斯坦福大学 CleanState 研究组提出的一种新型网络创新架构,可通过软件编程的形式定义和控制网络,具有控制平面和转发平面分离及开放性可编程的特点。
SDN 的核心理念是,希望应用软件可以参与对网络的控制管理,满足上层业务需求,通过自动化业务部署,简化网络运维。如果把现有的网络看成手机,那 SDN 的目标就是做出一个网络界的 Android 系统,可以在手机上安装升级,同时还能安装更多更强大的手机 APP。
SDN 并不是一个具体的技术,它是一种网络设计理念,规划了网络的各个组成部分(软件、硬件、转发面和控制面)及相互之间的互动关系。

SDN 的发展驱动力和优势
驱动力:
- 计算虚拟化驱动:静态到动态的网络变化。虚拟机迁移改变了原有静态的网络部署模式,需要网络开放出来,能与虚拟化业务互通起来随需而动,动态调整网络的策略的扩展性
- 云计算对资源的垂直整合:独立演进到协同。网络作为一种资源被云计算整合到基础架构中,提供快速连接的服务
- 云计算时代 IT 业务的发展,驱动由固定到可编程网络的快速变化
- 数据中心资源:需要随业务跨地域整合,并使数据中心间广域流量增大。而现状是数据中心资源分散,广域成本高且利用率低
优势:
- 统一便捷的管理,解决网络中设备越来越多样化问题
- 无缝的版本升级,解决设备版本升级对业务的影响
- 网络数据可视化
- 整体的流量调度

SDN 体系结构具有四个关键特征:
- 基于流的转发(Flow-based forwarding);
- 数据平面与控制平面分离(Separation of data plane and control plane);
- 网络控制功能位于数据平面交换机外部(Network control functions: external to data-plane switches);
- 可编程网络(A programmable network);
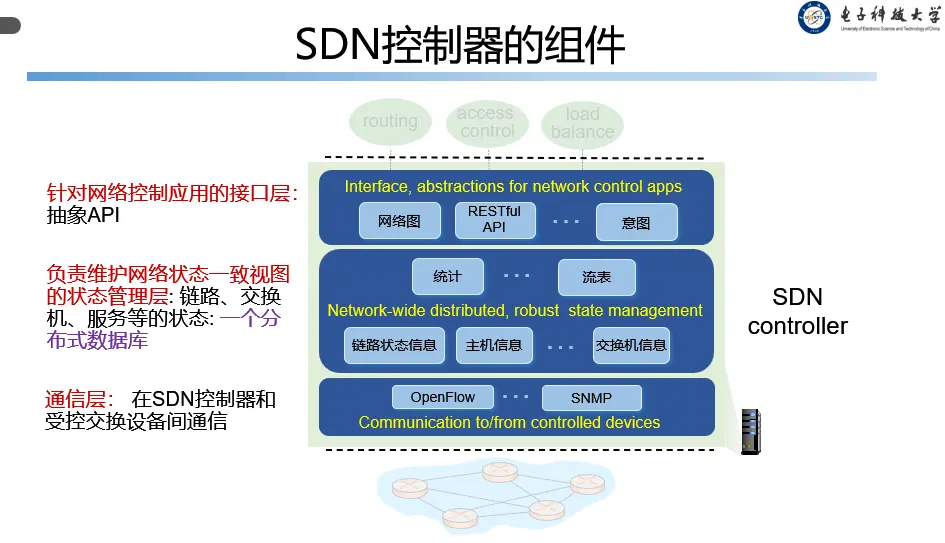
SDN 的核心思想是建立一个通用转发体系。每个交换设备包含一个流表(flow table). 流表由一个逻辑上中心化的控制器(远程控制器)来计算和分发
Ref
网络层控制平面 Network Layer:Control Plane
https://efterklang.github.io/UESTC/ComputerNetworking/Ch4-2NetworkLayer/