
Java Hashtable
Intro
如果你已了解 HashTable 相关的基本概念, 可以跳过本节.Next Part
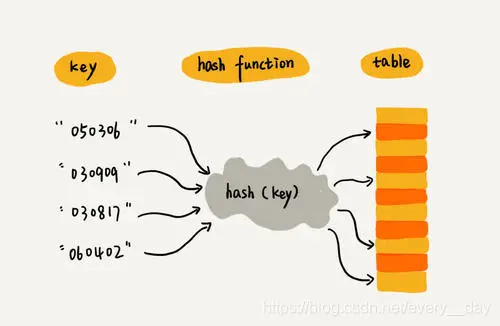
Hashtable 是一种数据结构, 用于存储键值对, 通过 key 来计算 index, 从而快速查找 value.
它以数组+链表或者数组+红黑树的形式来存储数据(在 Java 8 之后,当链表的长度超过一定阈值时,链表会转换为红黑树以提高性能), 通过 key 的 hashcode 来计算 index, 从而快速查找 value.
名词解释
- Buckets HashTable 内部有一个数组(Buckets),存放多个 Bucket,每个元素(也称为 bucket)存储键值对组(Key-Value Pairs),每个 Bucket 中存放着所有 HashKey 相同的(Key, Value);
ps:hash bucket 是一个概念,在 JDK 中其数据结构可为链表或者红黑树.引入 bucket 的目的是为了解决 hash 冲突. - Hash collision 哈希冲突/哈希碰撞,指不同的 key 通过哈希函数计算出相同的 index,这种情况称为哈希冲突。
hashCode()哈希函数,它接受一个键作为输入,并返回一个整数,该整数用作在数组中存储键值对的索引。设计哈希函数时,应使得哈希函数尽可能地均匀地分布,尽量让不同的 key 得到不同的 hashCode。- Key-Value Pair 这是存储在 HashTable 中的数据。每个键都是唯一的,并映射到一个值。
- index 索引.本文中指 通过 key 的 hashcode 计算出来的 index(index 应该小于 buckets 的长度), 用于定位 key-value pair 所在的 bucket
插入键值对流程
计算 index
在 Java 中,Object 类提供了一个方法 hashCode(),它返回对象的哈希码值。帮助确定对象应该存储在哈希表的哪个位置。
hashCode()的具体实现取决于对象的类。例如,对于String类,hashCode()方法计算字符串中每个字符的哈希码值,并将它们组合在一起。请注意,Objects 规范中,如果两个对象相等(根据
equals(Object)方法),那么它们的哈希码值必须相同。但是,两个对象的哈希码值相同时,两个对象不一定相等。这是因为可能存在哈希冲突,即两个不同的对象具有相同的哈希码值。
在哈希表中,我们首先需要通过 hashCode() 方法获取对象的哈希码,然后再通过取余操作将哈希码映射到哈希表的大小范围(即 bucketsLen)内。
取余对 HashCollision 的影响
JDK 源码中,取余操作的实现为:
1 | static int indexFor(int h, int length) { |
解决 HashCollision
插入键值对时,如果发生 index 相同,意味着发生了哈希冲突
冲突解决的方法有很多种,常见的有链地址法(每个 bucket 存储一个链表,新的键值对被添加到链表的末尾)和开放地址法(如果一个 bucket 被占用,HashTable 会寻找下一个可用的 bucket)。
JDK 中的 HashTable 使用的是链地址法,即每个 bucket 存储一个链表,新的键值对被添加到链表的末尾。JDK 1.8 之后,当链表的长度超过一定阈值时,链表会转换为红黑树以提高性能。
补充
取余对 HashCollision 的影响
基本概念
被除数 ÷ 除数 = 商 ... 余数被除数 mod|% 除数 = 余数除数>被除数,余数=被除数- 被除数: dividend
- 除数: divisor
- 商: quotient
- 余数: remainder
- 素数/质数: prime number, 除了 1 和它本身以外不再有其他的因数
- 因子: factor, 一个数的因子是能够整除它的数,例如 2 是 4 的因子,因为 4/2=2
- 合数: composite number, 除了 1 和它本身以外还有其他的因数
在哈希函数中,取余操作通常用于将大范围的哈希值映射到一个较小的范围,取余操作的结果是哈希值的分布可能会发生变化,这可能会影响哈希碰撞的频率。
给定数列作为 keys, 以及模数(被除数) n 作为 buckets 长度, 通过取余操作, 可以将数列的值映射到[0, n)的范围内。
$$a_n = 1+n*step, n \in N$$
取余操作可能会影响哈希碰撞的频率。除数选取素数可以减少哈希碰撞的频率。
如果 step 是 n 的因子,那么就容易发生哈希碰撞,哈希碰撞的间隔即为 step 的值。
例如,n = 6, step = 2, 那么哈希碰撞的间隔为 2, 即 index = 1, 3, 5 处会发生哈希碰撞.见代码示例
1 | step = 2, n = 6; |
数列的冲突分布间隔为因子大小,对于同样的随机数列,n 的因子越多,发生冲突的可能性就越大.故而,我们应该尽量避免因子过多的情况,如果情况允许,尽量选择素数作为除数。
Hashtable 快速取模方案
证明
对于二进制的位运算,整除 8(2 的三次方) 等价于右移三位
$0110 0100 >> 3 = (0000 1100)_2 = 12$ 即为商
而01100100的后三位$(100)_2 = 4$即为余数
已知$n = 2^m$,商为hash二进制数右移 m 位,而余数为hash的后 m 位
要求hash % n,即求hash的后 m 位,而n-1的二进制表示恰为 m 个 1,可推得hash & (n-1)等与hash % n
例题验证
(n-1) & hash,不妨设hash = 45367,二进制为 0100 1010 1111 0111,求hash % 8
45367 % 8 = 45367 & 7
为什么 java 中哈希表的大小是 2 的幂次方?
代码验证
在 JDK 中,Hashtable求模的方式为 hash & (n-1),这种方式的前提是 n 为 2 的幂次方,其他情况下未必成立.
1 | public class HashTable { |
1 | [INPUT = 16] |
hashMap 中的哈希函数
hash & (n - 1)跟取余运算hash % n结果是一致的。极端情况下,如果 hashMap 中存了几千万的数据。当某次插入数据引发扩容时,需要重新计算下标值,此时用位运算可以提高性能;
平常代码中使用,对于代码性能提升优化微乎其微,且会影响代码可读性
References
Java Hashtable